Candidates: Are you interviewing and need support?

AI Hiring Assistant
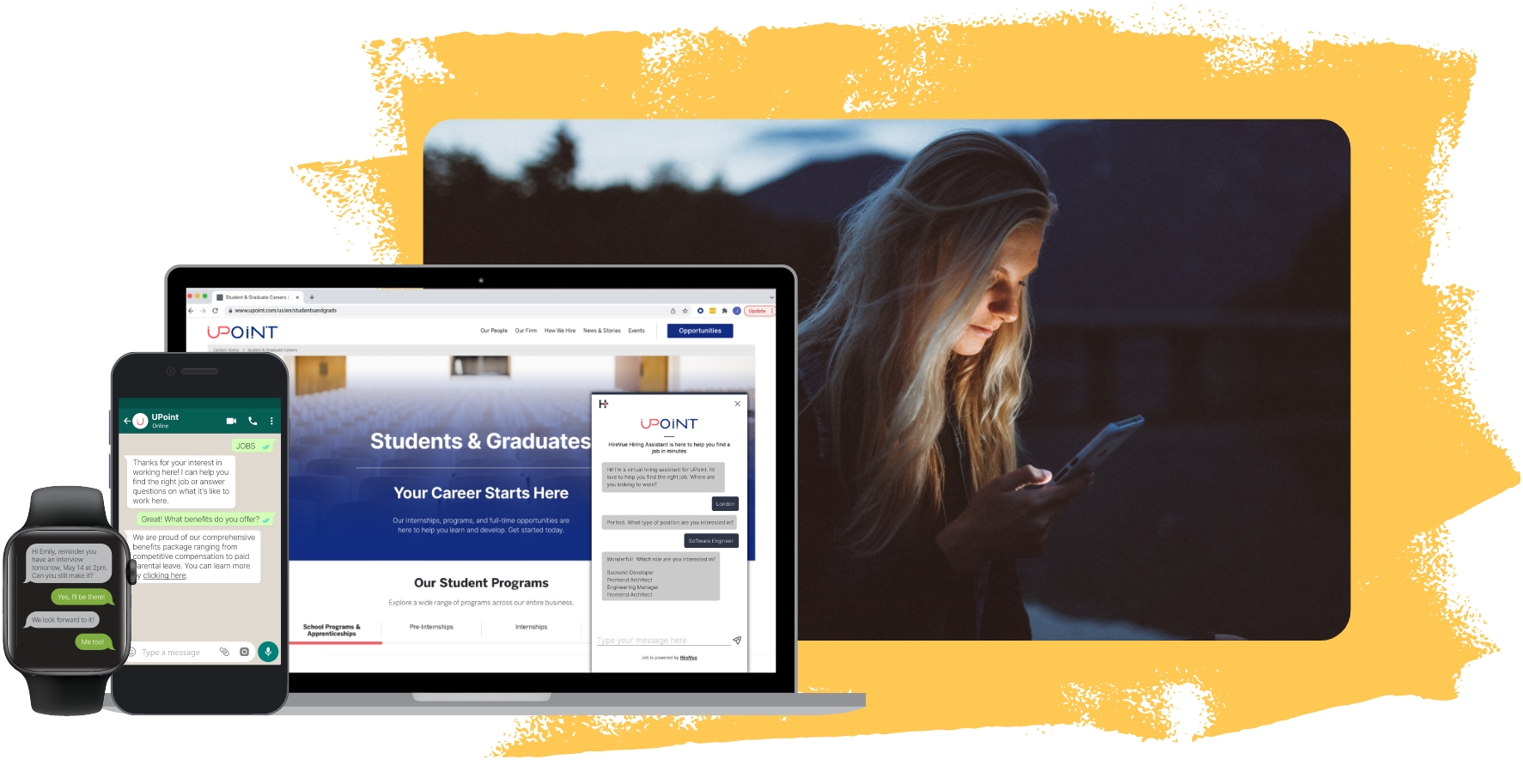
Rely on a 24/7 hiring assistant and get back to focusing on what matters…your candidates
HireVue’s Hiring Assistant can help candidates unlock their potential by matching their skills with available job opportunities. Our advanced matching capabilities ensure that tricky titles or confusing job descriptions don’t slow down the recruiting process.
“[HireVue] closed 66% of open requisitions in 2 weeks and has created an amazing experience for our restaurant. All of our applicants first talk with [the hiring assistant], and if qualified, are directly scheduled with the restaurant.”
4x Faster Time-To-Hire
24/7/365 Candidate Engagement
20%+ Improvement in Interview Show Rates
40% Increase in Recruiter Bandwidth


Stop disqualifying qualified talent
Candidates often struggle to find the right job because they don’t know where to start.
HireVue’s Conversational AI assistant ensures candidates’ skills are transferred and used to present all roles that fit their skill set, opening up more opportunities for them., Plus you’ll never worry about candidate ghosting, we’ll send them a text or WhatsApp with next steps within minutes of applying.

Power your workflows without the work
No one enjoys updating candidate ATS statuses or seeing candidates stuck in the pipeline. We’ll automatically progress candidates in your ATS after each candidate interaction and text them next steps. You’ll shave off days, even weeks, from your time-to-hire.

Stop chasing candidates and start hiring them
Stop ghosting candidates. Candidates lose interest when they don’t hear from you. Eliminate the time and effort it takes for recruiters to follow-up with automated SMS or WhatsApp invites, reminders and ongoing updates–and watch your conversion rates soar.
Texting defies the talent shortage.
Learn how one healthcare system does more with less time and resources.
Watch Now






Curious what you could save?
Calculate your ROI
Ready to transform your hiring?
Request Demo
© 2024 HireVue, Inc. All rights reserved.