Candidates: Are you interviewing and need support?

Our Science
Support fair, diverse hiring with Human Potential Intelligence
Hiring should be fair—and backed by science. The typical hiring process often shuts out the best candidates—but Human Potential Intelligence is rooted in science to create a fairer hiring landscape. While hiring AI may be new, the rigor behind it isn’t. Our innovative models are built on decades of science and over 70 million interviews—and look to the future of what’s possible for your workplace.

“We've added an ethics department to the organization to make sure we're helping to create a diverse environment that welcomes everyone. I feel like HireVue takes that task and that work off of my plate and allows me to rely on the technology to meet that standard. ”


Science, not guesswork
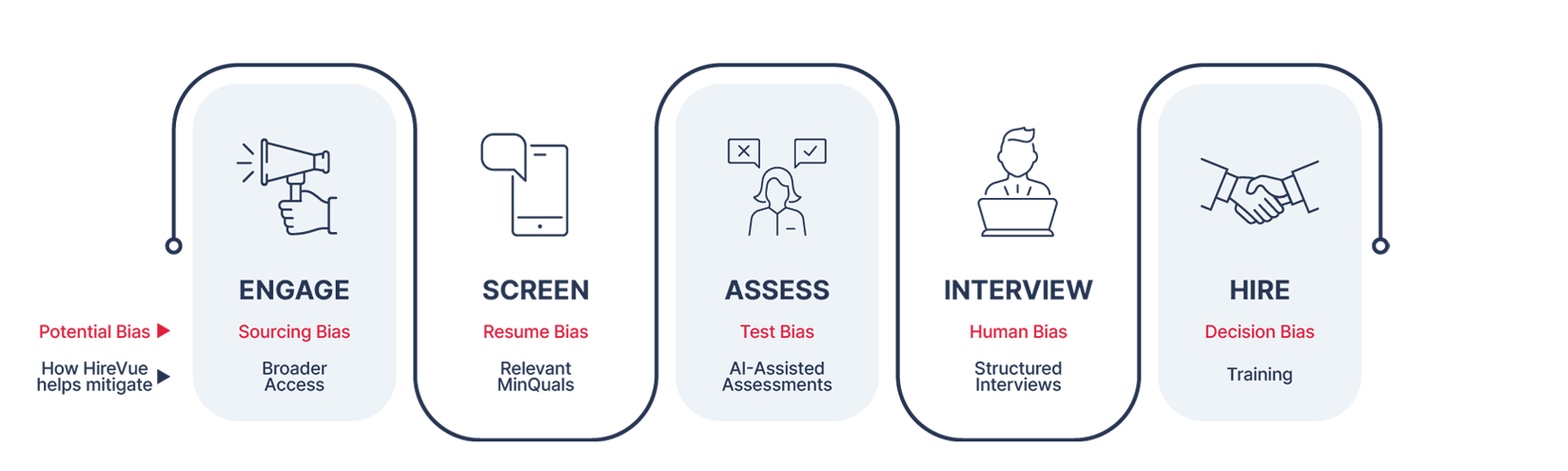
Legacy HR tech was built for speed and quantity, not quality—and it evaluated what was achieved, not what could be achieved in the future. At Hirevue we believe science, deployed correctly, is a major part of the solution. We’ve rejected the old standard and work to perfect AI-powered tech that benefits hirers and candidates. We believe hiring on attitude and aptitude for specific roles should be the preferred method—not a standardized job description. And only then, can teams start hiring for greatness—and that’s what we call Human Potential Intelligence.

Consistency of AI machine learning
Question and evaluation consistency matters when it comes to encouraging diversity in hiring. While humans try to be consistent, they are inherently inconsistent and things like familiarity bias can easily creep in. Machines, however, are consistent by design. Everyone is treated equally in a HireVue assessment: Candidates respond to the same questions, play the same games, and receive the same amount of time to prepare and answer. And, with ethically-designed algorithms, candidates’ responses are evaluated against identical criteria, every time.


Building on a foundation of data and experience
We’ve learned a lot by conducting over 70 million interviews. With this data, our models focus on skills, behaviors, and competencies specific to the job and not on irrelevant information like how someone was dressed, which university they attended, or which keywords are in their resume.
AI in a human-centric way
External AI experts, along with our data scientists and industrial/organizational psychologists, regularly check our AI models to mitigate for bias and encourage diversity in hiring.

Increasing Diversity in Hiring
For many of today’s leading organizations, it’s no longer enough to simply ensure your hiring process is compliant and doesn’t create adverse impact—true leaders want to drive toward creating a more diverse organization. A recent review of data from four long-term HireVue customers demonstrated that the Virtual Job Tryout® (VJT) can play a key role in these efforts. By comparing the make-up of the employee population before and after the implementation of the VJT, customers in multiple industries saw significant improvements in new hire diversity. On average, clients saw an increase of more than 40% in ethnicity and 26% in gender diversity.

The team
With over 30 experts, our science team combines two distinct fields of science: Industrial/Organizational Psychology and Data Science. We’ve carefully assembled experts from a range of experiences and fields as diverse as physics, economics, and medical imaging. Our team’s ongoing investigations into the use of advanced applied AI technology are regularly published in peer-reviewed scientific outlets.

Expert Advisors

Sheryl Falk
Litigation Attorney, Winston & Strawn
Sheryl, co-leader of the Global Privacy and Data Security Task Force at Winston & Strawn, brings significant investigation and litigation experience to her practice to navigate regulatory and litigation inquiries arising out of data security incidents. A former Assistant U.S. Attorney, she has 25 years of litigation experience before state and federal courts, as well as arbitrators. Sheryl concentrates her practice in data security, cyber and other internal investigations, trade secret litigation, and complex commercial litigation. She has significant experience helping clients protect data, from developing data security and trade secret protection procedures to responding to data security incidents and investigating trade secret theft claims. In her data security practice, she counsels clients on how to identify and mitigate business and legal risks arising out of these incidents. Her work has garnered recognition in Legal 500.

Tomas Chamorro-Premuzik
Chief Talent Scientist, ManPower Group
Dr. Tomas Chamorro-Premuzic is an international authority in psychological profiling, talent management, leadership development, and people analytics. He is the Chief Talent Scientist at Manpower Group, co-founder of Deeper Signals and Metaprofiling, and Professor of Business Psychology at both University College London, and Columbia University. He has previously held academic positions at New York University and the London School of Economics, and lectured at Harvard Business School, Stanford Business School, London Business School, Johns Hopkins, IMD, and INSEAD, as well as being the CEO at Hogan Assessment Systems. Dr. Tomas has published 9 books and over 130 scientific papers (h index 58), making him one of the most prolific social scientists of his generation.

Michael Campion
Prof. of Management Purdue University
Michael A. Campion is the Herman C. Krannert Chaired Professor of Management at Purdue University and the 2010 winner of the Scientific Contribution Award given by the Society for Industrial-Organizational Psychology. He is among the 10 most published authors in the top journals in his field for the last three decades and the second most cited author in textbooks in both I/O and Human Resource Management. He is past editor of Personnel Psychology (a scientific research journal) and past president of the Society for Industrial and Organizational Psychology (SIOP). In 2009, he was promoted to the Herman C. Krannert Chaired Professorship for contributions and productivity in scientific research. He is also the 2010 winner of the Scientific Contribution Award given by the SIOP, which is the lifetime scientific contribution award and most prestigious award given by SIOP. He manages a small consulting firm (Campion Consulting Services) that has conducted nearly 1100 projects for over 160 private and public sector organizations during the past 30 years on nearly all human resources topics.


Adhering to global standards
Our technology and science follow the professional guidelines and regulations to maximize fairness in the hiring process and support data privacy. We also continually monitor proposed regulations and laws, so we can help provide the right guidance to our customer base.
- Uniform Guidelines on Employee Selection Procedures (UGESP)
- Equal Employment Opportunity Commission (EEOC)
- The Age Discrimination in Employment Act of 1967 (ADEA)
- Americans with Disabilities Act of 1990 (ADA)
- General Data Protection Regulation (GDPR)
- Data security
- Privacy
Want to learn more about our standards and principles?

Our science rigor drives our audits
HireVue rigorously tests every algorithm before it’s put into production to minimize bias towards race, gender, or any other protected groups. Once the algorithms are live with our customers, they are checked regularly to monitor for bias and assist with diversity hiring efforts.

© 2024 HireVue, Inc. All rights reserved.